Cloudera Data Engineering
Build, orchestrate, and govern enterprise-grade data pipelines with Apache Spark on Iceberg. Power scalable AI and multi-function analytics from clouds to data centers.

OVERVIEW
The open standard of enterprise data engineering
Data Engineering empowers enterprise teams to securely build, automate, and scale data pipelines on the foundations of an open lakehouse. Power multi-function analytics and AI for data anywhere.
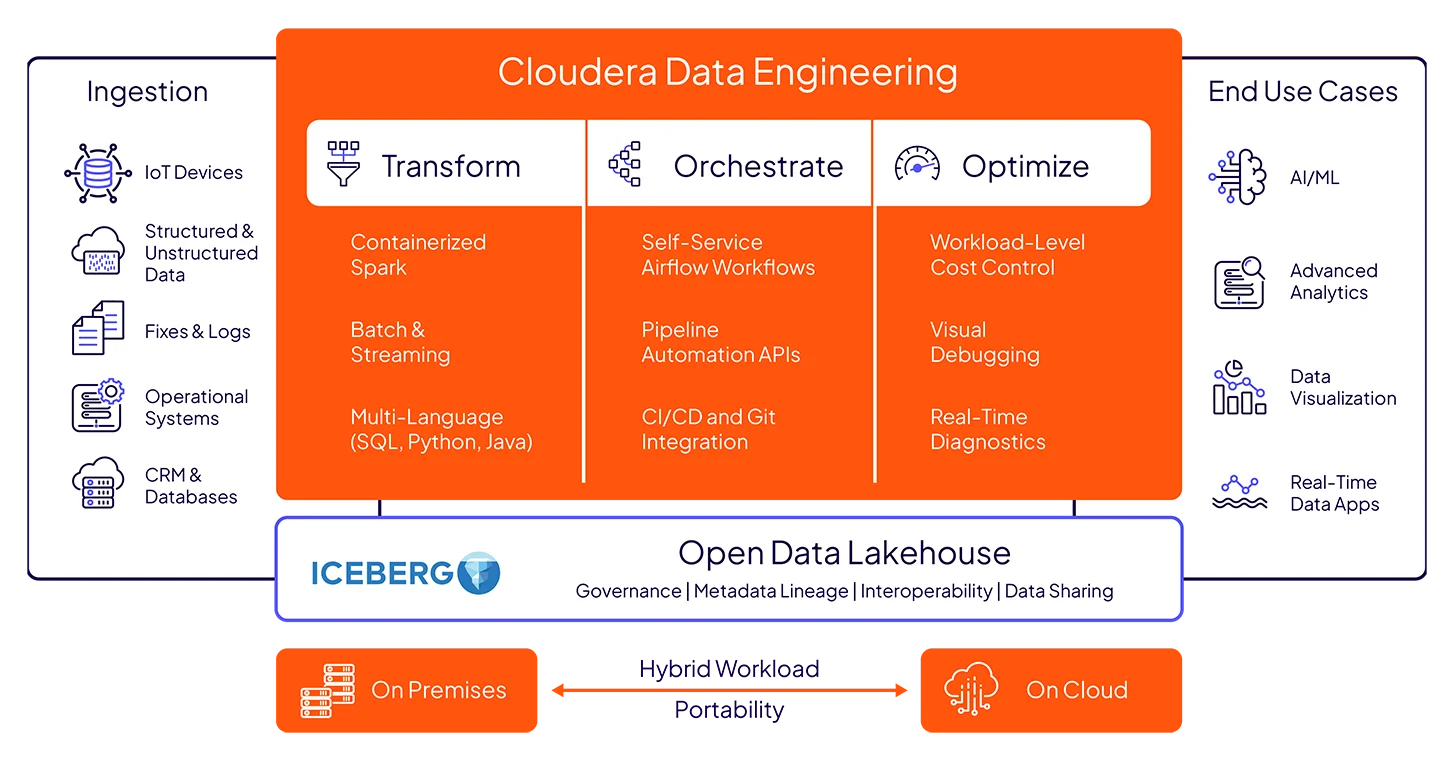
Unify structured and unstructured data with Apache Spark on Iceberg, orchestrated through Airflow—fully open, no vendor lock-ins.
Build, run, and manage data pipelines anywhere—clouds, data centers, or hybrid environments—with containerized flexibility and unified governance.
Achieve cost efficiency with financial governance tools for resource optimization, including workload-level observability, autoscaling, and zero-ETL data sharing.
USE CASES
Build end-to-end data pipelines to accelerate AI and analytics.
-
Build scalable pipelines for data anywhere
Bring workload portability, open standards, and scale across cloud and on premises.
-
Accelerate DataOps with orchestration
Automate workflows, iterate pipelines, and simplify collaborations.
-
Zero-ETL data sharing
Empower secure, trusted data access internally and externally.
-
Monitor and optimize pipeline costs
Lower TCO with observability and efficient compute.
-
Build scalable pipelines for data anywhere
Bring workload portability, open standards, and scale across cloud and on premises.
-
Accelerate DataOps with orchestration
Automate workflows, iterate pipelines, and simplify collaborations.
-
Zero-ETL data sharing
Empower secure, trusted data access internally and externally.
-
Monitor and optimize pipeline costs
Lower TCO with observability and efficient compute.
20%
enhanced data team efficiency
Boost efficiency with portability, orchestration, and unified data access from Cloudera on premises.
Run Spark, Iceberg, and Airflow from anywhere, with cloud-native data engineering experience.
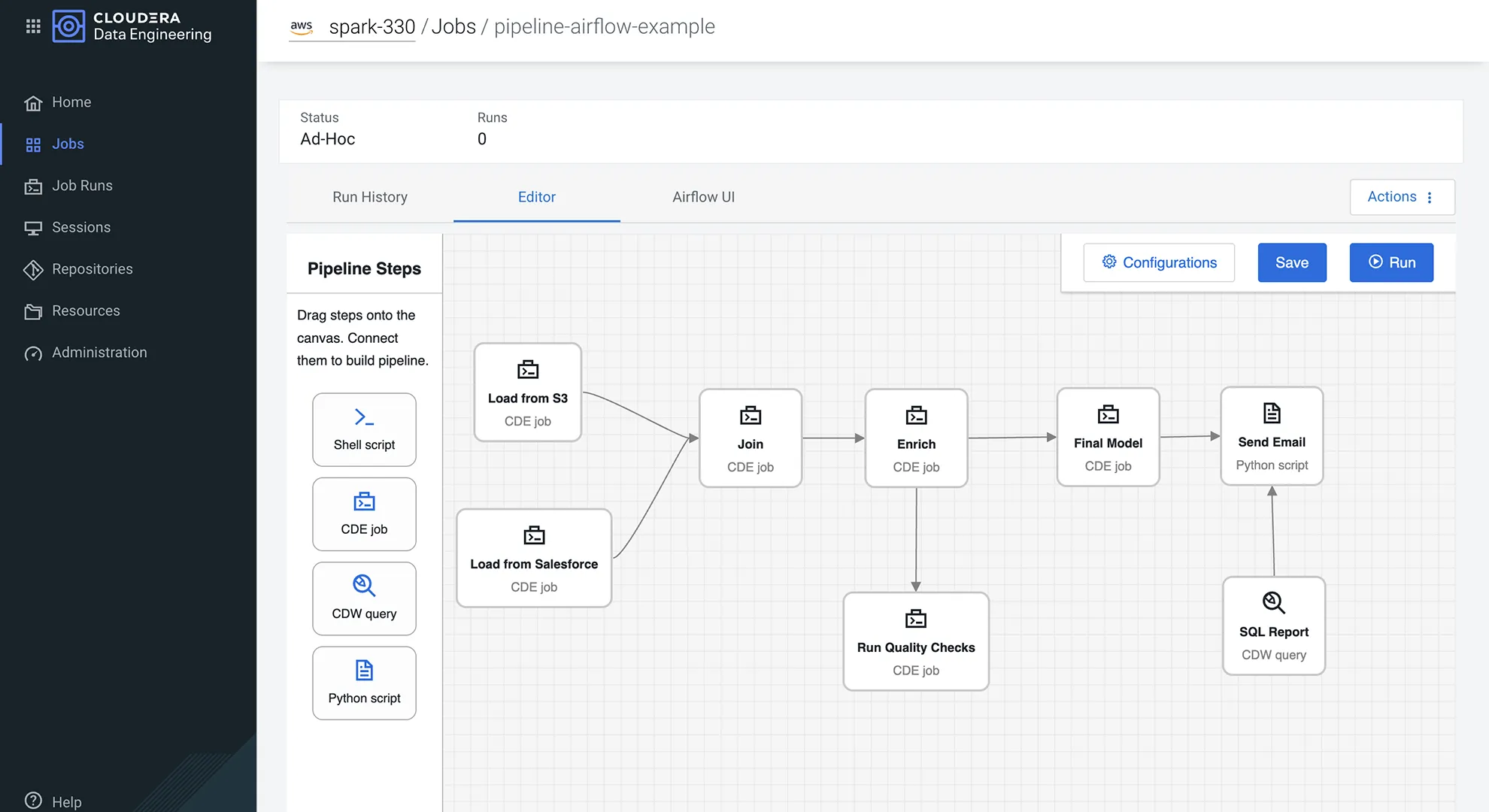
Boost practitioner productivity with intuitive and enterprise-secured tooling
Build, test, and orchestrate pipelines with Sessions and Apache Airflow.
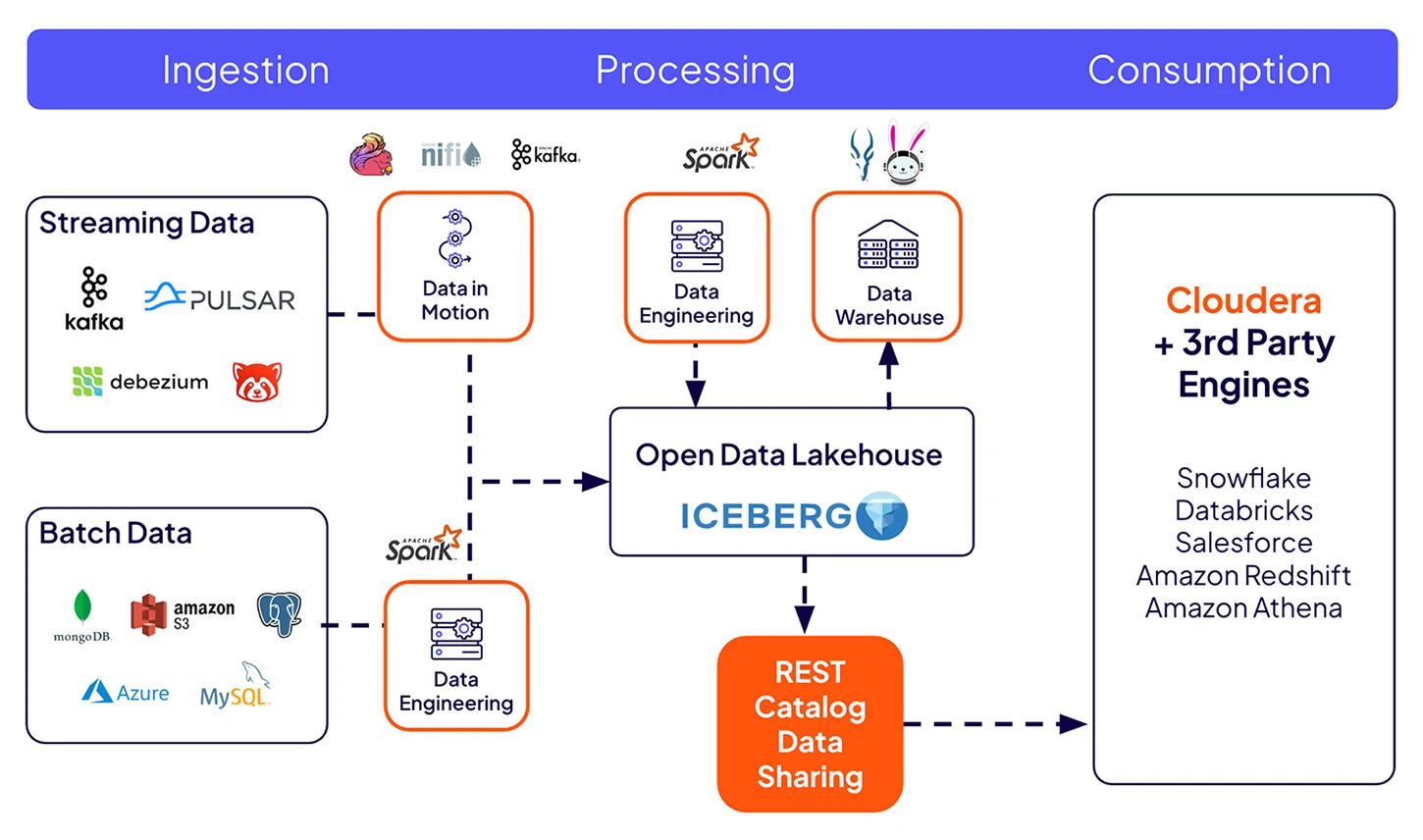
Deliver fresh data to downstream pipelines and external platforms.
Connect to external engines via Iceberg REST Catalog with metadata governance and lineage.
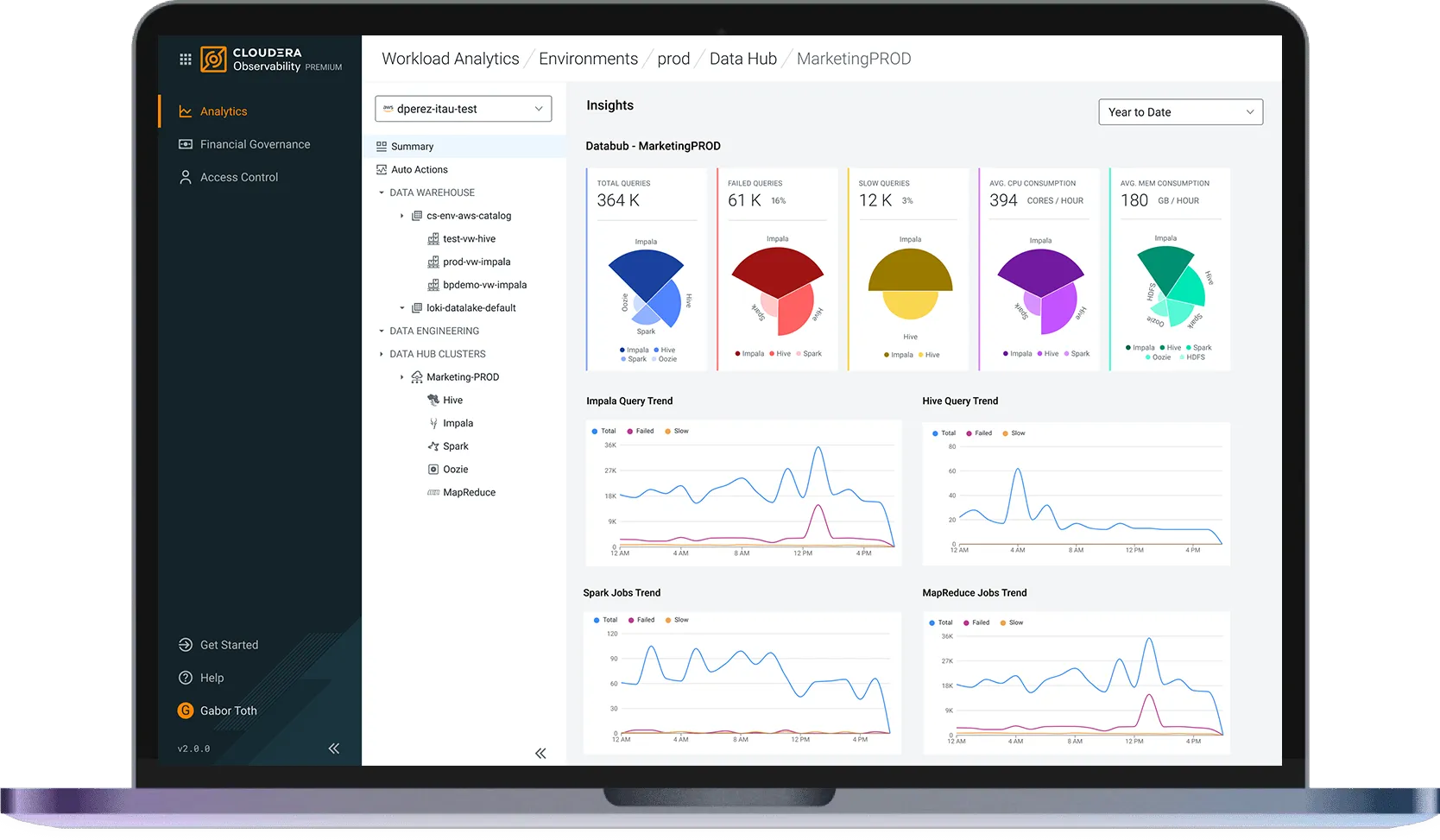
Scale smarter with workload-level financial governance
Optimize costs with built-in insights and energy-efficient AWS Graviton processors.
Migrating to Apache® Iceberg For Dummies
Read this step-by-step blueprint for migrating your workloads to Apache Iceberg.

Run scalable, governed pipelines with Spark on Iceberg in containers from the open data lakehouse. Leverage Iceberg’s schema revolution, time travel, and external data sharing across on-premises or cloud environments.
Drag-and-drop orchestration for complex workflows, simplifying task management, dependency control, and external tool connectivity.
Spin up on-demand sessions for rapid testing and iterations. Enable remote, secure development from any IDE—e.g., VSCode and Jupyter Notebook—powered by Spark Connect.
Keep data fresh by capturing row-level changes from source systems. Automate continuous updates to build reliable data pipelines.
Monitor data pipelines end-to-end with integrated lineage and metadata management. Powered by Cloudera Shared Data Experience (SDX) and Cloudera Data Lineage for automated visibility, governance, and trusted insights across hybrid environments.
Automate pipeline workflows across any service with robust APIs—whether you're working in SQL, Java, Scala, or Python. Quickly diagnose and resolve performance issues with real-time visual profiling, complete with built-in monitoring and alerting for every lifecycle stage.
Features by type of Cloudera Data Engineering cluster
| Core cluster | All-purpose cluster | ||
Infrastructure |
Autoscaling cluster | ||
| Spot instances | |||
| Cloudera Shared Data Experience | |||
| Open lakehouse with Iceberg | |||
Spark |
Job lifecycle management | ||
| Centralized monitoring | |||
| Workflow orchestration (Airflow) | |||
| Spark streaming | |||
Development endpoints |
Interactive sessions | ||
| External IDE connectivity | |||
| JDBC connector (coming soon) | |||
Agent-ready Data to Power Your AI
Build your next AI agent, powered by your enterprise data, in a secure and controlled way.

Cloudera Data Engineering deployment options
Unified processing layer on an open, hybrid data lakehouse.
Cloudera on cloud
- Multi-cloud flexibility: Deploy across public clouds with containerized, API-first services—no lock-in and fully interoperable.
- Modular developer experience: Use Apache Airflow, managed Spark, APIs, and IDEs—accelerate development with iterative collaborations.
- Elastic scalability: Autoscale Spark workloads dynamically and optimize costs based on usage.
Cloudera on premises
- Own your deployment: Deploy across public clouds with containerized, API-first services—no lock-in and fully interoperable.
- Cloud-ready experience: Get the same modular, containerized services as cloud—built for hybrid portability and scale.
- Built for enterprise: Leverage fast onboarding, external IDE access, and fine-grained access controls by default.
CUSTOMERS
Trusted by teams to turn hybrid data into business impact.
 transportation
GEODIS
transportation
GEODIS
 financial services
Nord/LB
financial services
Nord/LB
 manufacturing and automotive
International
manufacturing and automotive
International
Connectors, integrations, and partners.
Build pipelines on an open, interoperable data ecosystem. Integrate with leading engines, cloud providers, and tools across your modern data stack.
Data processing
Data lakes & warehouses
Data orchestration
Streaming ingestion
NoSQL engine
Data lakes & warehouses
Cloud service provider
Cloud service provider
Cloud service provider
Cloud service provider
Container orchestration
Data warehouse
Take the next step
Dive into the details and explore the powerful capabilities of Cloudera Data Engineering.
Data Engineering product tour
Get an inside look at Cloudera Engineering in a tour of the product.
Data Engineering documentation
Dive into the details of how to get up and running with Cloudera Data Engineering.
Explore more products
Analyze massive amounts of data for thousands of concurrent users without compromising speed, cost, or security.
Make smart decisions with a flexible platform that processes any data, anywhere, for actionable analytics and trusted AI.
Accelerate data-driven decision making from research to production with a secure, scalable, and open platform for enterprise AI.
Collect and move your data from any source to any destination in a simple, secure, scalable, and cost-effective way.